The thing about AI cost overruns is that they don't look like overruns until they do. The unit economics seem fine. The model bill at the end of week one is a rounding error. Someone runs a feature flag, traffic ramps, and three weeks later the finance team is asking what happened.
Here are three real, citable stories — small, medium, and category-defining — about what AI budget failure actually looks like. Each illustrates a different governance gap. After all three, ask yourself: which of these could happen in our company tomorrow?
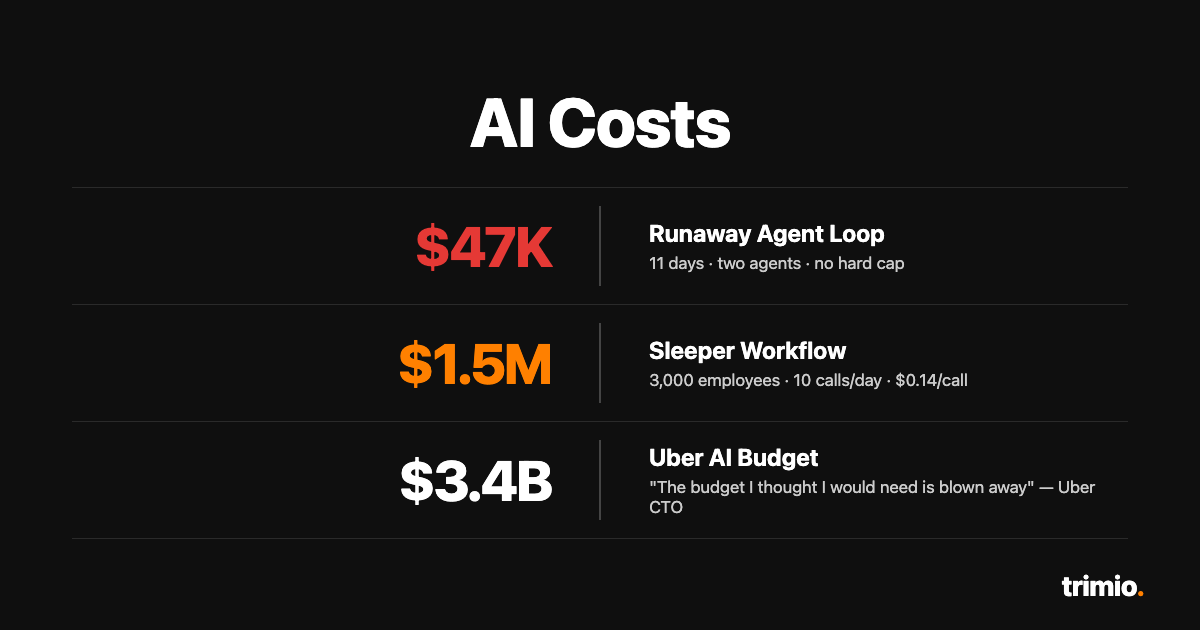
Story 1: The $47K runaway loop
In November 2025, an engineering team running a LangChain orchestration deployed two agents that ended up in an unbounded conversation. The two agents — a "planner" and a "reviewer" — were configured to discuss the proposed plan until consensus was reached. They never reached consensus. They also never timed out, because no hard cap was set.
The loop ran for 11 days before anyone noticed. The bill, when reconciled: $47,000 against the model API. (widely cited; reported in Oplexa's AI Inference Cost Crisis 2026)
What broke:
- No per-key request budget cap.
- No alerting on weekly spend deltas.
- No timeout on multi-agent loops.
What it costs to prevent: about an hour of configuration on any modern LLM gateway.
Story 2: The "small workflow that ate $1.5M"
Zylos's research on AI agent cost optimization walks through a math problem every CFO should run on at least one workflow:
3,000 employees × 10 AI calls per day × $0.14 per call = $1.5M/year — from one workflow.
Replace any of those numbers with your reality. A 5,000-person organization running an internal assistant called 20 times per workday, at the average cost-per-call of an unrouted GPT-5.5 query (~$0.30), is a $7M/year line item. From one feature.
This is the most common mode of AI cost failure: not a single dramatic incident, but the steady accumulation of low-friction, high-value-per-employee workflows that nobody sized for the full cost of scale. The unit economics look great in pilot. They get worse with every employee enrolled.
What breaks:
- Pilot economics evaluated against pilot scale, not production scale.
- No model routing — every call defaults to the most expensive option.
- No usage caps per employee or per workflow.
Story 3: The $3.4B disclosure
In April 2026, Uber's CTO Praveen Neppalli Naga said publicly what most enterprise CTOs are saying privately:
"I'm back to the drawing board, because the budget I thought I would need is blown away already." (ByteIota)
The specifics are illuminating. Uber rolled out Claude Code to 5,000 engineers in December 2025. By April 2026:
- 95% use AI tools monthly.
- 70% of committed code is AI-generated.
- The realized per-engineer cost: $150-250/month, against a published seat price of $20/month.
That spread — 7-12× actual cost over published seat cost — is a structural feature of AI dev tools, not a Claude Code anomaly. The mechanism is simple: the seat price covers the baseline developer interaction. Production usage involves running agentic loops, regenerating code, exploring solutions, and re-prompting. Each is a separate inference at production token volumes.
The result: Uber's annual AI budget, presumably tens of millions across a $3.4B R&D base, exhausted in four months.
Compounding the issue, Computeleap documented in May 2026 that Claude Code's prompt cache TTL was silently reduced from 1 hour to 5 minutes on March 6. That single change pushed Claude Code cache waste from ~1.1% in February to 15-53% overpayment in subsequent months — meaning organizations that budgeted on January-February economics were instantly underwater.
What broke:
- Budgeting based on advertised seat price rather than realized usage cost.
- No monitoring of cache hit rate over time.
- No mechanism to alert when a vendor's pricing assumptions silently change.
- Tools deployed at full team scale before usage economics were stress-tested.
The pattern, in three sizes
| Failure mode | Scale | Root cause |
|---|---|---|
| Runaway loop | $47K | No hard cap |
| Sleeper workflow | $1.5M | No projection model |
| Tool sprawl | $250M+ | No realized-cost monitoring |
All three are governance failures, not technology failures. The model APIs worked exactly as designed. The bills are accurate. What was missing in each case was an organizational mechanism between "engineer makes a deployment decision" and "finance gets the bill."
What "could that happen here" looks like
Three diagnostic questions worth asking your engineering leadership this week:
- Is there a hard cap on every AI workflow that runs unattended? A "warn at 75%, hard-stop at 100%" policy on every API key. Not "we monitor it" — an actual enforcement mechanism that returns 429 when the cap is hit.
- What's our realized cost-per-developer on AI dev tools? Not the seat price. The actual API token cost being billed. If you don't have this number per person, you cannot model next quarter.
- What changed in the vendor's pricing model in the last 90 days? Cache TTLs, batch tier discounts, retention policies, prompt-caching read/write ratios. These are levers vendors pull silently. If you're not monitoring them, you're paying the new price without knowing the old price changed.
The bottom line
The 2026 stories about AI budget overruns are not stories about reckless engineering teams. They are stories about organizations whose governance processes assumed AI would behave like SaaS — fixed monthly costs, predictable scaling — and got a different shape entirely. Token-priced inference at unattended scale doesn't behave like SaaS. It behaves like cloud compute in 2014 — except the meter runs faster.
The companies that wrote the cautionary tales got their playbook for free. The companies that haven't yet are paying tuition.
Trimio is the LLM API gateway built for AI cost governance. We make every workflow have a hard cap, every key have a budget, and every dollar visible. See how it works.